Medical AI Superintelligence Test (MAST) Leaderboard
The MAST project seeks to curate a centralized resource of robust and realistic clinical benchmarks to measure the performance of medical AI.
See our methodology and submission instructions.
Dec 2025
Feb 2026
Mar 2026
Apr 2026
CPC-BenchMultimodal Derm
May 2026
~Jul 2026
In Development
NOHARM-Mind
~H2 2026 – 2027
In Development
PACT: 12 high-risk clinical reasoning benchmarks
Benchmark Demos
View all ›First Do NOHARM v2
SCT-Bench
MedAgentBench v2
PhysicianBench
ReXrank Mini
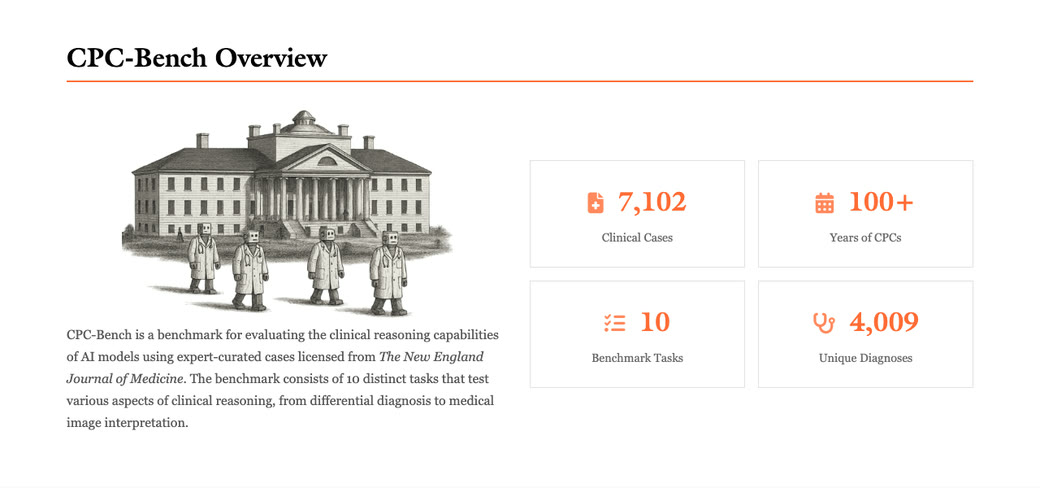
CPC-Bench
First Do NOHARM v2
SCT-Bench
MedAgentBench v2
PhysicianBench
ReXrank Mini
CPC-Bench
First Do NOHARM v2
SCT-Bench
MedAgentBench v2
PhysicianBench
ReXrank Mini
CPC-Bench
First Do NOHARM v2
SCT-Bench
MedAgentBench v2
PhysicianBench
ReXrank Mini
CPC-Bench
Preview: MAST is currently in preview. Exact scores on this benchmark may change as we undergo final validation and tuning.
First Do NOHARM v2 overall metric across 14 models
Benchmark Comparison
Overall scores across benchmarks
R² = 0.33
Model Profiles
Compare models across benchmarks
Not all models could be run on every benchmark; axes with no result are shown as an open circle at the center.
Performance Over Time
No scored data for the current selection.
No scored data for the current selection.
Preview: MAST is currently in preview. Exact scores on this benchmark may change as we undergo final validation and tuning.
Model Leaderboard
Top 10 shown
| # | Model | Reasoning↓ | Safety | Agentic | Images | Multimodal | CPC | Diagnostic | Management | Radiology |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GPT-5.5 | 75.4%±2.2 | 73.4%±4.3 | 56.7%±4.6 | 42.9%±2.8 | 49.2%±1.8 | 86.2%±3.7 | 75.1%±3.3 | 76.2%±2.6 | 57.6%±0.0 |
| 2 | GPT-5 | 72.1%±2.4 | 67.2%±5.2 | 32.4%±11.1 | 44.2%±2.5 | 47.6%±1.5 | 80.3%±4.5 | 73.1%±3.9 | 73.2%±2.8 | 51.6%±0.0 |
| 3 | GPT-5.2 | 71.8%±2.2 | 70.6%±4.7 | 27.2%±10.0 | 46.5%±2.7 | 49.3%±1.5 | 82.8%±3.9 | 72.6%±3.3 | 71.7%±2.7 | 52.4%±0.0 |
| 4 | GPT-5.4 | 71.3%±2.2 | 72.4%±4.2 | 38.8%±5.2 | 46.5%±2.5 | 47.1%±1.3 | 82.5%±4.2 | 71.9%±3.5 | 70.6%±2.8 | 47.8%±0.0 |
| 5 | Claude Opus 4.7 | 70.1%±2.6 | 67.2%±4.8 | 40.6%±5.1 | 42.7%±2.3 | 48.0%±1.5 | 76.7%±4.9 | 75.4%±3.5 | 67.9%±3.6 | 54.7%±0.0 |
| 6 | Kimi K2.6OSS | 66.3%±2.9 | 63.9%±4.9 | -- | -- | -- | 73.9%±5.7 | 73.1%±3.9 | 63.1%±4.0 | -- |
| 7 | Claude Opus 4.6 | 66.1%±2.9 | 57.9%±5.5 | 44.4%±5.1 | 40.4%±2.7 | 42.7%±1.5 | 76.0%±5.0 | 75.4%±3.6 | 63.8%±3.7 | 45.2%±0.0 |
| 8 | GPT-5 mini | 66.0%±2.4 | 62.1%±4.9 | 19.0%±10.7 | 43.2%±2.4 | 46.1%±1.4 | 77.9%±4.5 | 68.2%±3.8 | 65.9%±2.9 | 49.4%±0.0 |
| 9 | Claude Sonnet 4.6 | 64.8%±2.9 | 57.7%±5.4 | 35.0%±5.5 | 39.0%±2.8 | 39.7%±1.5 | 76.2%±4.8 | 72.7%±3.5 | 62.9%±3.6 | 40.4%±0.0 |
| 10 | Kimi K2.5OSS | 63.4%±2.9 | 60.7%±5.2 | 11.1%±8.8 | 41.7%±2.8 | 47.0%±1.8 | 68.7%±5.4 | 69.3%±4.0 | 60.8%±3.7 | 53.8%±0.0 |
Not all models could be run on every benchmark; blank (NA) cells indicate no result, not a zero score.